

LLM hallucination detection challenges and a attainable resolution introduced in a distinguished analysis paper
Lately, giant language fashions (LLMs) have proven spectacular and rising capabilities, together with producing extremely fluent and convincing responses to consumer prompts. Nevertheless, LLMs are identified for his or her skill to generate non-factual or nonsensical statements, extra generally often called “hallucinations.” This attribute can undermine belief in lots of situations the place factuality is required, reminiscent of summarization duties, generative query answering, and dialogue generations.
Detecting hallucinations has all the time been difficult amongst people, which stays true within the context of LLMs. That is particularly difficult, contemplating we normally don’t have entry to floor reality context for consistency checks. Extra info on the LLM’s generations, just like the output likelihood distributions, can assist with this activity. Nonetheless, it’s usually the case the place one of these info is unavailable, making the duty much more tough.
Hallucination detection has but to be solved and is an energetic space of analysis. On this weblog put up, we’ll current the duty on the whole and its challenges and one attainable strategy revealed within the analysis paper SELFCHECKGPT: Zero-Useful resource Black-Field Hallucination Detection for Generative Massive Language Fashions[1]. We’ll illustrate among the approaches introduced within the paper with actual examples, mentioning some execs and cons of every technique. You may evaluation the examples your self by going to this Google Colab Pocket book.
This weblog will cowl:
- What Is LLM Hallucination
- The Strategy: SelfCheckGPT
- Consistency Examine
1. BERTScore
2. Pure Language Inference
3. LLM Immediate - Experiments
- Conclusion
- References
What Is LLM Hallucination
In pure language technology, hallucination might be outlined as “generated content material that’s nonsensical or untrue to the supplied supply content material”[2]. The supply content material can signify totally different capabilities for various duties. For instance, for summarization duties, the supply is the enter textual content being summarized, whereas for generative question-answering duties, the supply is taken into account the world data[2]. Let’s concentrate on the question-answering activity and try one instance of a consumer query and the reply given by OpenAI’s GPT mannequin (text-davinci-003):
Person Immediate: Who was Philip Hayworth?
LLM Response: Philip Hayworth was an English barrister and politician who served as Member of Parliament for Thetford from 1859 to 1868.
At first sight, that appears like a coherent response, however after some time, we’d ask ourselves a really cheap query: is it true?
We don’t have a lot info to reply our new query, although. We don’t have a context with confirmed details we will use to confirm the assertion. LLMs are usually skilled underneath a large corpora of texts, and it may be laborious to confirm if the assertion is grounded in a specific supply of data. A fast Google search doesn’t present any hits for an individual matching the response. What precisely constitutes a hallucination remains to be not nicely established, however this instance may very well be understandably thought-about a hallucination as a result of the topic with this title, location, and employment could not have existed at all.
Let’s do that once more with one other query:
Person Immediate: Who’s Invoice Gates?
LLM Response: Invoice Gates is a expertise entrepreneur, investor, and philanthropist. He’s the co-founder of Microsoft Company and is among the wealthiest individuals within the world.
Okay, these statements are a lot simpler to confirm and are supported by a fast examine on Wikipedia, so that is unlikely to be a hallucination. Throughout coaching, it is extremely seemingly that the LLM has seen a number of statements about Invoice Gates, so the next tokens after “Invoice Gates is _” will seemingly be generated with excessive confidence. Alternatively, the LLM may not ensure about which phrases to make use of after “Philip Hayworth is _”. This perception permits us to hyperlink uncertainty with factuality, as factual sentences will seemingly comprise tokens predicted with a better likelihood when in comparison with hallucinated sentences. Nevertheless, we’d not have the output likelihood distribution at hand for a superb variety of instances.
The instance and content material of the present session was based mostly on the unique paper [1], and we are going to proceed to discover the paper’s strategy within the following sections.
The Strategy: SelfCheckGPT
All through the final part, we thought-about two necessary issues for our strategy: entry to an exterior context and entry to the LLM’s output likelihood distribution. When a way doesn’t require an exterior context or database to carry out the consistency examine, we will name it a zero-resource technique. Equally, when a way requires solely the LLM’s generated textual content, it may be referred to as a black-box technique.
The strategy we need to speak about on this weblog put up is a zero-resource black-box hallucination detection technique and is predicated on the premise that sampled responses to the identical immediate will seemingly diverge and contradict one another for hallucinated details, and can seemingly be related and in line with one another for factual statements.
Let’s revisit the earlier examples. To use the detection technique, we’d like extra samples, so let’s ask the LLM the identical query three extra instances:

Certainly, the solutions contradict one another — at instances, Philip Hayworth is a British politician, and in different samples, he’s an Australian engineer or an American lawyer, who all lived and acted in numerous durations.
Let’s examine with the Invoice Gates instance:

We are able to observe that the occupations, organizations, and traits assigned to Invoice Gates are constant throughout samples, with equal or semantically related phrases being used.
Consistency Examine
Now that we’ve got a number of samples, the ultimate step is to carry out a consistency examine — a method to decide whether or not the solutions agree with one another. This may be performed in plenty of methods, so let’s discover some approaches introduced within the paper. Be at liberty to execute the code your self by checking this Google Colab Pocket book.
BERTScore
An intuitive strategy to carry out this examine is by measuring the semantic similarity between the samples, and BERTScore[3] is a technique to do this. BERTScore computes a similarity rating for every token within the candidate sentence with every token within the reference sentence to calculate a similarity rating between the sentences.
Within the context of SelfCheckGPT, the rating is calculated per sentence. Every sentence of the unique reply will likely be scored in opposition to every sentence of a given pattern to seek out essentially the most related sentence. These most similarity scores will likely be averaged throughout all samples, leading to a ultimate hallucination rating for every sentence within the unique reply. The ultimate rating must have a tendency in direction of 1 for dissimilar sentences and 0 for related sentences, so we have to subtract the similarity rating from 1.
Let’s present how this works with the primary sentence of our unique reply being checked in opposition to the primary pattern:

The utmost rating for the primary pattern is 0.69. Repeating the method for the 2 remaining samples and assuming the opposite most scores have been 0.72 and 0.72, our ultimate rating for this sentence can be 1 — (0.69+0.72+0.72)/3 = 0.29.
Utilizing semantic similarity to confirm consistency is an intuitive strategy. Different encoders can be utilized for embedding representations, so it’s additionally an strategy that may be additional explored.
Pure Language Inference
Pure language inference is the duty of figuring out entailment, that’s, whether or not a speculation is true, false, or undetermined based mostly on a premise[4]. In our case, every pattern is used because the premise and every sentence of the unique reply is used as our speculation. The scores throughout samples are averaged for every sentence to acquire the ultimate rating. The entailment is carried out with a Deberta mannequin fine-tuned to the Multi-NLI dataset[5]. We’ll use the normalized prediction likelihood as an alternative of the particular lessons, reminiscent of “entailment” or “contradiction,” to compute the scores.[6]
The entailment activity is nearer to our objective of consistency checking, so we will anticipate {that a} mannequin fine-tuned for that objective will carry out nicely. The creator additionally publicly shared the mannequin on HuggingFace, and different NLI fashions are publicly obtainable, making this strategy very accessible.
LLM Immediate
Contemplating we already use LLMs to generate the solutions and samples, we’d as nicely use an LLM to carry out the consistency examine. We are able to question the LLM for a consistency examine for every unique sentence and every pattern as our context. The picture under, taken from the unique paper’s repository, illustrates how that is performed:
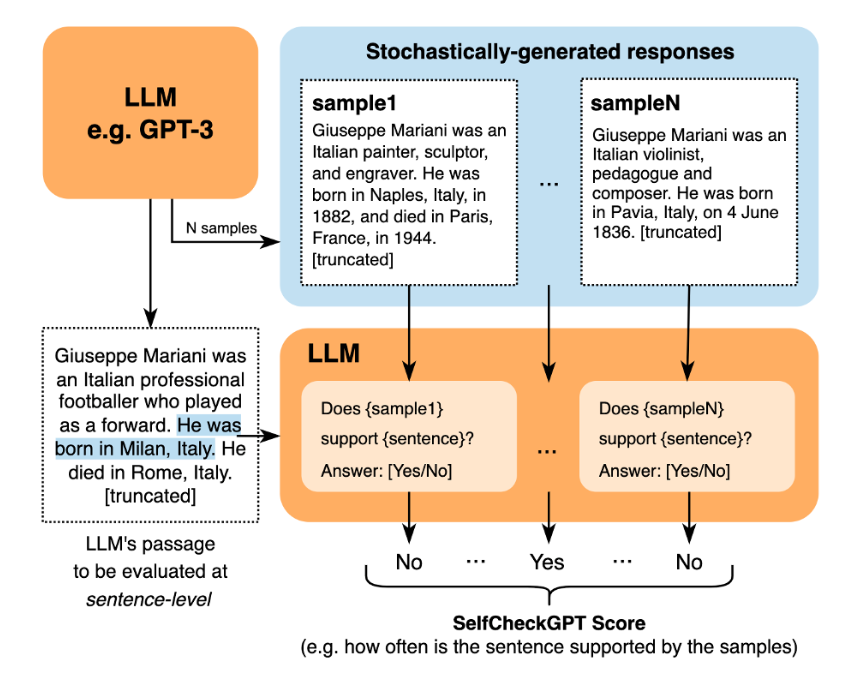
The ultimate rating might be computed by assigning 1 to “No”, 0 to “Sure”, 0.5 for N/A, and averaging the values throughout samples.
In contrast to the opposite two approaches, this one incurs additional calls to the LLM of your selection, which means further latency and, presumably, further prices. Alternatively, we will leverage the LLM’s capabilities to assist us carry out this examine.
Experiments
Let’s see what we get as outcomes for the 2 examples we’ve been discussing for every of the three approaches.
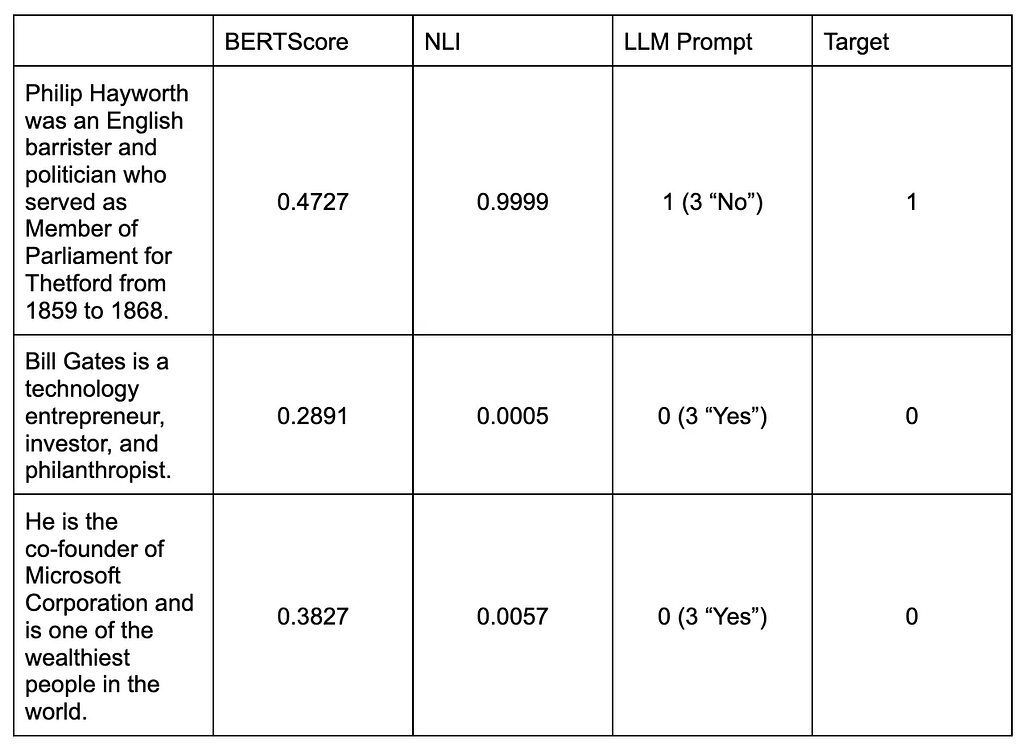
These values are solely meant for example the strategy. With solely three sentences, it’s not purported to be a method to match and decide which strategy is finest. For that objective, the unique paper shares the experimental outcomes on the paper’s repository right here, which incorporates further variations that weren’t mentioned on this weblog put up. I received’t go into the main points of the outcomes, however by all three metrics (NonFact, Factual, and Rating), the LLM-Immediate is the best-performing model, carefully adopted by the NLI model. The BERTScore model appears to be significantly worse than the remaining two. Our easy examples appear to comply with alongside the traces of the shared outcomes.
Conclusion
We hope this weblog put up helped clarify the hallucination drawback and offers one attainable resolution for hallucination detection. This can be a comparatively new drawback, and it’s good to see that efforts are being made in direction of fixing it.
The mentioned strategy has the benefit of not requiring exterior context (zero-resource) and likewise not requiring the LLM’s output likelihood distribution (black-box). Nevertheless, this comes with a price: along with the unique response, we have to generate additional samples to carry out the consistency examine, rising latency and price. The consistency examine may also require further computation and language fashions for encoding the responses into embeddings, performing textual entailment, or querying the LLM, relying on the chosen technique.
References
[1] — Manakul, Potsawee, Adian Liusie, and Mark JF Gales. “Selfcheckgpt: Zero-resource black-box hallucination detection for generative giant language fashions.” arXiv preprint arXiv:2303.08896 (2023).
[2] — JI, Ziwei et al. Survey of hallucination in pure language technology. ACM Computing Surveys, v. 55, n. 12, p. 1–38, 2023.
[3] — ZHANG, Tianyi et al. Bertscore: Evaluating textual content technology with bert. arXiv preprint arXiv:1904.09675, 2019.
[4] — https://nlpprogress.com/english/natural_language_inference.html
[5] — Williams, A., Nangia, N., & Bowman, S. R. (2017). A broad-coverage problem corpus for sentence understanding via inference. arXiv preprint arXiv:1704.05426.
[6] — https://github.com/potsawee/selfcheckgpt/tree/important#selfcheckgpt-usage-nli
Understanding and Mitigating LLM Hallucinations was initially revealed in In the direction of Information Science on Medium, the place persons are persevering with the dialog by highlighting and responding to this story.

{kind=link}